
Understanding prompt engineering may not require rethinking generalisation

Tldr: When learning over prompts, classic PAC-Bayes bounds are extremely tight; more so than any previous PAC-Bayes analysis of deep networks.
Zero-shot performance of visual-language models
An emerging paradigm in deep learning is to use large pre-trained models such as CLIP or ALIGN as feature extractors and provide weak supervision for a downstream target task via prompts, which are text descriptions of the desired tasks or concept to classify. This performs remarkably well – up to 75% accuracy on ImageNet. This has led to handcrafting of prompts or prompt engineering. When practitioners attempt to engineer prompts for a dataset - they often are not concerned with overfitting to the test set. In recent work: https://arxiv.org/abs/2310.03957 we illustrate that in-fact you can’t overfit.
Observation: Given how small the vocabulary sizes and context lengths of such visual-language models are, the hypothesis class is relatively small compared to what is often studied in generalisation of neural networks. For example, the VC dimension of neural networks is typically lower bounded by the number of parameters - in direct conflict with the paradigm of large models.
Numerical non-vacuous bounds in deep learning
Whereas obtaining non-vacuous bounds for deep neural networks still remains a technical challenge when done on the weight space. Given a fixed image encoder, the text encoder of CLIP, for instance, is an injective map of the prompts to the weights of a linear classifier. One could evaluate classic PAC-Bayes bounds on the prompts. I show here the classic PAC-Bayes bound [McAllester 1999].
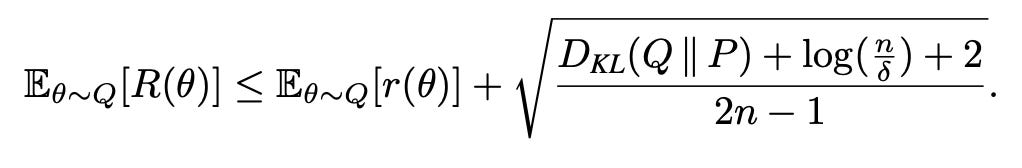
The dominant term is the KL divergence of the posterior from the prior. CLIP for instance has a vocabulary of about 50,000 tokens and a context length of 77. A uniform prior means that KL term = 77 ∗ log(49408). Note we're now operating in the discrete space of language tokens. This implies on a dataset like CIFAR-10 with 50000 training examples, 10 classes - we have a bound of ~30% on the risk any prompt-based classifier with 99% confidence. This is already much tighter than bounds we typically get for neural networks.
Clearly, we can do better with a more informative prior - e.g. a language model. Here’s a plot of the PAC-Bayes bound using the LLamA-7B as the prior. The way to interpret the plot is if the true risk according to the bound, is equal to the empirical risk - then all the points will be on the dotted line.

This tells us if we simply use the prompt - a photo of a {class_name} for all the 1000 classes in ImageNet - our true risk will be no more than ~30% with high probability. Cool!
What’s the catch? Well these bounds rely on the fact that pre-trained visual-language models already contain some hypothesis class that will perform well on the training set - and the generalisation of the underlying models themselves is not being analysed but what this does provide is solid evidence for why the wide-spread practice of prompt-engineering is as principled as you can get from a statistical learning theory perspective.